Embarrassingly automatable as the first step of legacy modernization

In it, DWD employees explain the IT systems that support Wisconsin’s unemployment insurance program. The demonstration, which walks through a typical unemployment claim process, is painful to see. What employees have to deal with just to get their regular jobs done every day is so repetitive and prone to error, it’s hard to convey how bad it is without seeing it yourself. Their tasks are tedious and take a long time to complete, in part due to the many manual steps, but also because of the slow processing of the underlying mainframe-based system, which was first built some 50 years ago. So it can add days or weeks to the receipt of an unemployment benefit, which compounds when demand is high like during COVID.
The software engineer in me was crying out watching the employees show all the laborious things they have to do to process a claim, like copying and pasting values over and over into different form fields, remembering and inputting obscure codes without any help, validation, or indication of correctness from the system, and using external programs like Excel to perform simple calculations required by the business rules.
Everything they were showing could be automated, trivially so in most cases. No new system would be designed this way. Wisconsin employees only find themselves in this lamentable situation due to the system’s age, poor overall design, and the fact that changes over the years were apparently accreted on top instead of having the system be redesigned continually with contemporary technologies and user interfaces in response to new requirements.
Watching this scene unfold, I was reminded of when a certain kind of programming task is referred to as “embarrassingly parallel.” This is when a large set of data can be broken down into smaller independent chunks and sent for processing across a number of different CPUs at the same time, called in parallel, which speeds up processing greatly and doesn’t require too much effort on the part of the programmer. This Wisconsin situation appears to be “embarrassingly automatable.” It has tasks that are rote and that would be trivial for a computer program to reproduce mechanically, and tasks that are pieces of a process that are subject to a high rate of error by a human operator due to manual entry.
The people in Wisconsin who use and administer this system recognize how bad it is and know it needs to change; that was the point of the video and the motivation behind an RFP they issued to replace the system. Replacing it fully is a big job that will take a long time. If you view full replacement as a journey, these manual processes that readily lend themselves to automation indicate a first step toward that goal.
Making a modest investment into picking off embarrassingly automatable tasks can realize a lot of value sooner, and at the same time provide real guidance on the path toward full replacement. Having a new modern system that enables Wisconsin to better serve the public is the high-level goal, the north star by which all present activity should navigate. But comparatively low-level improvements to the current system, like better automating existing workflows to speed them up and reduce errors, need not be at odds or distract from that future desired end goal.
Perhaps it’s time for an equivalent of Maslow’s classic hierarchy of needs, but for legacy modernization projects. This could help us classify foundations and layers of approaches upon which to build that are universal to any system rework. Instead of physiological needs, like food, shelter, and sleep, which are the bottom of Maslow’s pyramid, we might have reducing toil and automation as the first layer for legacy modernization.
A day in the life of the Wisconsin unemployment insurance system
As of the summer of 2021, the Wisconsin unemployment insurance IT system is largely the same system that was first built in the 1970s. It runs on an IBM mainframe, with most business logic and user interfaces evolved from the original terminal screens and facilities provided 50 years ago. The state is currently working on a plan to modernize the system in a way that better serves all its users. Until then, the staff at the DWD and Wisconsin state residents are stuck with a system that heaps toil on staff and prevents the public from getting timely status updates. Here’s an example of how some types of unemployment insurance claims are processed. (You can see a lot more detail in the video from the Wisconsin DWD.)
- A person seeking an unemployment insurance benefit files a claim via the DWD website. This claim is processed in a batch job overnight by the mainframe system. During that processing, the system is unavailable for DWD staff to access.
- If the claim is initially rejected, such as for a lack of supporting documentation, a state claims adjudicator sits down at their computer the next day and pulls up the rejected claim in a monochrome mainframe terminal screen.
- The terminal display of the rejected claim info is cryptic and requires the employee to retain extensive domain knowledge as well as memorize codes, abbreviations, allowable actions, and what workflow steps are next. The terminal screen doesn’t give them any help here. The codes, for example, are not validated at the point of entry, despite the system having complete knowledge of them.
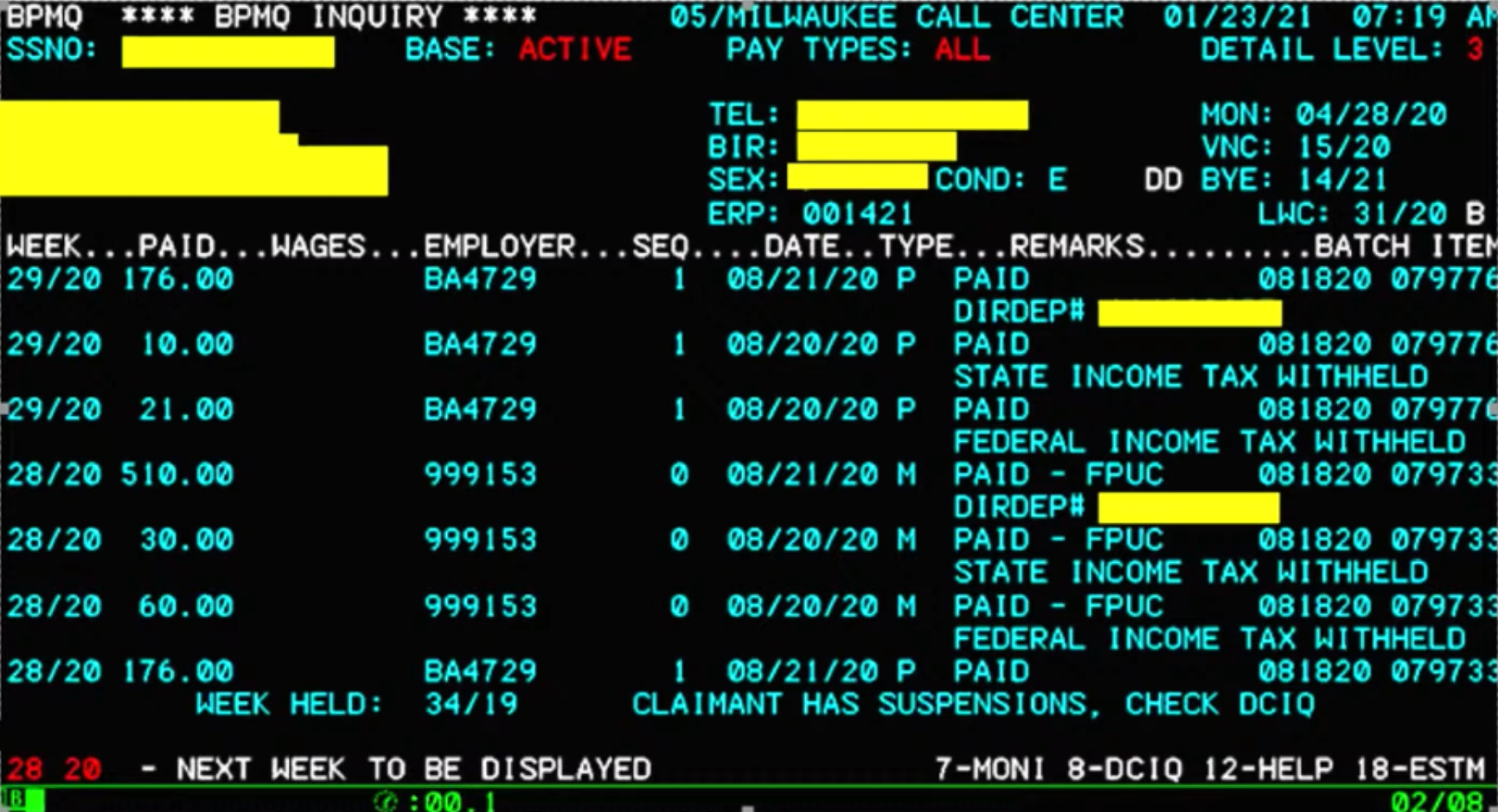
- The adjudicator advances through a series of screens, each providing a narrow lens on the overall claim. When entering info into text fields, no indication is given to the adjudicator regarding maximum length, so inputs can be truncated, and basic line-editing features don't exist, so already-entered input is overwritten.
- At key stages in the workflow, other related systems take over intermediate processing, and the adjudicator must manually re-enter data into them, creating another opportunity to introduce errors.
- Excel is not formally part of the workflow, but the adjudicator uses it to perform calculations that the main system cannot perform but are required to move forward. Again, this requires copying and pasting data and manual re-entry.
- Even if adjudicators can efficiently navigate this process, many steps are gated by the need to wait for the next overnight batch jobs to run, which forces adjudicators to wait until the next day to continue the process. If any data validation or logic errors were introduced, they’re often only discovered after the batch has run, resetting that step and delaying the process another day.
- An expensive manual review and validation step, requiring additional staff and time, is often performed prior to submitting data back into the system because it’s worth it to catch errors rather than wait for them to propagate through and delay the process again.
This process is filled with embarrassingly automatable tasks, from linking data systems together, to form validation, to on-demand data processing that would eliminate overnight batch jobs. Surely there are many additional ways to improve this system, but legacy modernization plans can start by addressing these sources of toil to provide immediate benefits to internal and external users.
Identifying embarrassingly automatable tasks to reduce toil
We all recognize toil - work that is repetitive but requires the operator’s attention, and which doesn’t change much over each iteration. Toil detracts from a system’s overall success, because it wastes time and is error-prone. Dealing with toil is typically not the best use of someone’s skills and capabilities; staff is therefore poorly utilized. Eliminating toil should be an end in and of itself for any automation effort.
Here are some common embarrassingly automatable tasks:
- Copying and pasting from one system to another, usually in form fields
- Manually entering in codes (short sequences of letters and numbers corresponding to known conditions data records can be in) from memory or reference instead of having them enumerated (and therefore validated) and represented in a list or drop-down menu
- Relying on an external system to handle a critical part of the workflow (this is where copy-pasting into Excel often shows up) or not providing trivial assistance (eg., calculations relevant to the domain) such that the user must resort to a supplemental system
- Not validating user-entered input at the point of input (i.e., only discovering an input validation error later after additional processing)
- Not providing user feedback on valid bounds of their data entry (eg., the max number of characters in a text field)
Finding and addressing these problems can have a huge impact on the error rate and throughput of a system before teams take on the much more challenging task of completely replacing a legacy system through something like a strangler fig pattern. In addition, this work can help address a common problem for legacy systems: the key logic of the system is not in the system, nor modeled by it or represented by it. Instead, it “lives” in the head of the operator or is encoded in a manual or shared knowledge between colleagues. That is no way to operate critical government systems.
How can organizations achieve this kind of automation? What we’re talking about here would be one or more new programs that consolidate a set of discrete steps from an existing workflow by interviewing and observing a staff person perform their task. The programs would take user input as necessary, performing calculations and validations that were previously encumbered by the operator, and interacting with the original system on the backend automatically. There is prior art for this kind of UI automation, and in fact, modern screen-scraping, browser scripting, and RPA tools could be all or part of the solution.
With a legacy mainframe terminal, it’s somewhat more challenging, due to the arcane interfaces and protocols involved, but there’s nothing theoretically preventing it. Modern programs can connect to mainframes remotely via TN3270 communication, and use text processing to detect form fields and simulate user input.
You might be reasonably concerned about the state employees for whom automation could threaten their jobs. Aside from the fact that the Wisconsin video is from state employees wishing to improve and replace the system they have to use, automating toil frees them to apply their energies towards higher-order challenges and tricky corner cases. It also frees their mental focus to longer-term improvements and possibilities. Let the computer be good at what computers are good at, and let the humans be good at the rest.
“If you automate a broken process…”
When discussing ways to improve legacy computer systems, it’s not uncommon to hear something to the effect of, “if you automate a broken process, all you get is a faster broken process.” This phrase correctly advises organizations that greater outcomes can be realized by challenging assumptions, revisiting the way things are “always done,” and redesigning processes based on user needs and program goals. There is a nuance here, though. If teams approach automating existing processes as the first step in moving up the pyramid of needs for legacy modernization, it can provide critical information for future improvements, as well as genuinely improving things, albeit perhaps at the margins, for real users.
Automating existing processes that involve a lot of toil can realize immediate value in the context of the current system. If the purely manual version of a process takes, say, 5 days to complete, and automating some or all of those steps (i.e., just taking them as they are but having a computer perform them mechanically) changes this to 5 hours — well, then that is undeniably a win for the program and the beneficiaries of it. This is especially important in systems like unemployment insurance when delays mean real pain for beneficiaries. In times of increased demand, like during COVID, delays can quickly compound and overwhelm the system. Each marginal improvement in processing efficiency therefore increases the overall throughput of how many claims can be processed and reduces the likelihood of exponentially worsening service times.
Addressing these embarrassingly automatable tasks can also indicate API boundaries and abstraction layers. This automation often looks like gathering up a number of individual steps and grouping them into a discrete function, parameterized by a few input variables (eg., the name of the claimant, their SSN, etc.), such that when the function is executed it arrives at the same outcome as the individual steps. That is almost by definition an API.
Hiding complexity behind a simplified interface is the nature of APIs. We know from experience that good API design is hard. It’s a devilish challenge to generalize a task for a broader set of users from a specific one, and one of the indicators of a good API is that it is extracted from proven use-cases and a collection of smaller actions that are regularly used. In this way, if you just repeatedly automated your toil, you would over time naturally discover the APIs that constitute the primary interface to your system.
In addition, documentation falls out naturally. Automated scripts and programs can be de facto documentation of your system. The process of analyzing the discrete manual steps and automating them can yield documentation that will have tremendous value to your organization.
We want to suggest that automating existing processes is not an end in and of itself, but a necessary first step. A waypoint up the hierarchy of legacy modernization needs. It’s an indicator to keep going, to build more abstraction layers that constitute a well-designed and well-factored application that is easier to modify and adapt.